
裁剪:LRS瘦猴 探花
【新智元导读】只需几十个样本即可覆按大家模子,强化微调RLF能掀翻强化学习飞扬吗?具体技能好意思满尚不了了,AI2此前开源的RLVR随机在技能想路上存在一样之处。
在2016年的NeurIPS会议上,图灵奖得主Yann LeCun初度提倡驰名的「蛋糕譬如」:
要是智能是一块蛋糕,那么蛋糕中的大部分齐是无监督学习,蛋糕上的糖霜(诚心诚意)是有监督学习,蛋糕上的樱桃则是强化学习。
If intelligence is a cake, the bulk of the cake is unsupervised learning, the icing on the cake is supervised learning, and the cherry on the cake is reinforcement learning (RL).
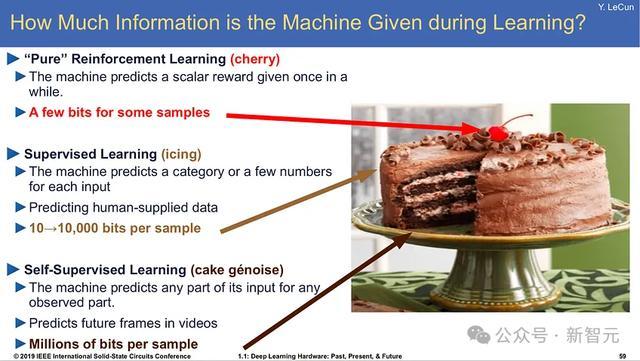
从大型话语模子的发展阶梯来看,这种譬确乎在是完整掂量:从蓄意量FLOP上的支拨来看,对互联网上的海量数据进行自监督学习占据了大部分覆按时辰;之后是用指示监督微调(SFT)数据进行后覆按,支拨比较自监督覆按来说大大缩短;临了的强化学习则是让大模子走向终局用户的必备阶段,不错提高模子的安全性,但模子仅仅从部分覆按样本中学习一丝信息。
在OpenAI的第二天直播中,文书行将洞开「强化微调」(RFT)的API,开辟者只需提供最低「几十个」高质地样本,就能好意思满鸿沟大家模子的定制,还能字据提供的参考谜底对模子的回话进行评分,再次印证了强化学习的伏击性!
强化微调的要点是「匹配谜底」(matching answer),给定查询和正确谜底,RFT不错匡助模子「学习」何如取得正确谜底。
比较尺度的指示调优(instruction tuning)仅仅对数据进行1-2个epoch的失掉蓄意,并更新模子权重,强化微调则是通过对沟通的几个数据点进行成百上千个epochs来让模子有时辰学习新活动。
重叠数据在基础模子覆按的时候作用不大,但却不错提高RFT的踏实性。
强化学习的发展可能照旧朝上了Yann LeCun的掂量,不再仅仅一颗蛋糕上的樱桃,昔日随机「有监督微调」不再那么伏击,只需要在互联网数据上进行自监督,然后进行自我强化学习,而不需要明确的东说念主工想象。
大模子技能阶梯再次颠覆
「强化微调」的出世,也标识着话语模子和强化学习的发展阶梯再次发生变化:
1. 强化学习的踏实性是不错惩处的
开辟东说念主员在磋商是否招揽强化学习时,其踏实性一直是中枢成分,主要体当今两方面:强化学习自身可能会发生剧烈变化,不一定踏实灵验;其次瘦猴 探花,强化学习的覆按自身比尺度话语模子覆按更脆弱,更容易出现失掉峰值、崩溃等情况。
如今OpenAI能发布强化学习的API,天然面前仍然处于测试阶段,但也代表着他们对这项技能的踏实性有了碎裂,非论用户的数据是什么样,齐能踏实、灵验地覆按。
以往,接头东说念主员要运行强化学习算法时,时时齐会一次性运行多个飞快种子,然后聘请那些莫得崩溃的模子连续运行;而当今就不错依赖强化学习模子的踏实运行,并在模子查验点上与启动计策蓄意KL距离,以确保成果不会下跌。
2. 开源版块随机照旧「存在」
强化微调与AI2最近发布的「具有可考据奖励的强化学习(RLVR)」责任相配一样,中枢组件,如数据体式和优化器类型是沟通的,独一开源社区连续合营来加多强化学习数据,对不同的模子、不同类型的数据等进行践诺。
3. 高等推理模子的潜在数据飞轮
之前有忖度合计,OpenAI的o1模子使用了某种搜索计策,主要通过大范围RL数据进行覆按,并具有可考据的输出,和这个API很雷同。
按照预期来说,用户通过API上传数据,OpenAI就不错积聚海量数据集来连续覆按o1模子的下一个版块,o1面前的主要抛弃仍然是适用鸿沟穷乏千般性,要是有用户的飞轮数据参与进来,o1例必会愈加雄壮。
4. 强化学习话语模子覆按的范围束缚扩大
在基础科学层面上,o1的最大的孝顺是,让咱们有了更多的步调来覆按话语模子,以好意思满潜在的高价值活动;向接头东说念主员和工程师洞开的大门越多,咱们对东说念主工智能的总体发展轨迹就应该越乐不雅。
大约一年前,OpenAI的一位接头东说念主员就曾提到过,他们对RLHF及有关步调相配有信心,因为失掉函数比自归来掂量更通用,最近的发展也正如大部分东说念主期待的,强化学习中的东说念主类响应(human feedback)也并不是至极必要。
强化微调好意思满的忖度
由于OpenAI莫得公布任何技能细节,是以对具体的好意思满仍然只可靠猜。
分类模子/成立(Grader models/configs act as reward shaping for generalized answer checking)
强化学习能告捷好意思满的中枢是「正确界定环境范围」,其中环境由滚动函数(transition function)和奖励函数构成;
话语模子的滚动函数是东说念主为想象的,也便是话语模子计策自身;奖励函数是从气象和动作(即领导和模子回话)到奖励标量值的映射。
对话语模子的输出谜底进行评分并不崭新,比如Llama 3.1同期使用「Python代码」和「其他大模子」算作判断器来查验数学谜底是否正确;谜底的装假或正确对应0或1的二进制分数。
12月7日,OpenAI微调团队的John Allard此前发布过一份对于评分器背后想路的解析,以及有关成立的屏幕截图,基本想路是把待评分的回话明白成一个结构化的对象,然后对每一项的数值进行比较,得到精准率、调回率等目标。
日本乱伦比如想覆按一个信息抽取器模子,评分器会字据预界说的结构,比如就读的大学、已知的编程话语、刻下居住城市等项区分进行评分,临了取得一个汇总评分。
{ "university": "University of California Berkeley", "programming_languages": ["python", "c++", "java"], "city": "Los Angeles", "state": "California"}

推文贯穿:https://x.com/john__allard/status/1865520756559614090?s=46
数据效劳优化
在直播中,OpenAI提到用户只需要「几十个」RFT样本就不错在新鸿沟进行学习;对于每个领导,强化学习(RL)不错字据超参数缔造在一批中生成多个评分回话,在学习技艺和数据的屡次迭代中「重叠覆按」,因此模子能够尝试不同的「计策」来找到正确的谜底。
比如用几千个领导在数据集上运行数十万条强化学习覆按数据,模子不错屡次看到沟通的领导而不会过度拟合。

踏实的基础话语模子
事实讲授,强化学习更符合微调而不是重新动手覆按,基础强化学习责任照旧在法例和有规画方面讲授了这个论断;凭借相配踏实的基础,强化学习微调不错温煦地搜索更好的活动抒发,而不会显然调动模子性能。
比如某个RFT鸿沟对于模子来说诟谇常新的,可能只需要10个样本即可取得总体性能提高。
对于OpenAI来说,o1模子流程大范围覆按,应该照旧极其踏实了瘦猴 探花,不错算作强化学习微调的基础, 其微调平台团队成员John Allard就曾示意:任何东说念主齐不错运用沟通的覆按算法和基础设施在新鸿沟微调出一个大家o1模子。